

《支付结算系统高效对接异构数据库全流程解析与实战指南》 ,支付结算系统对接异构数据库需解决数据格式、协议差异与性能瓶颈三大核心问题,首先通过统一数据模型(如JSON Schema或Protobuf)实现格式标准化,并采用中间件(如Apache Kafka或Debezium)进行实时数据同步,针对MySQL、Oracle等不同数据库,通过JDBC/ODBC连接器或API网关完成协议转换,同时利用分库分表、读写分离策略提升吞吐量,安全层面需加密传输(TLS)并实施字段级脱敏,实战中建议分阶段实施:先完成核心交易表的双向同步,再逐步扩展至风控与报表模块,最终通过压力测试验证高并发场景下的稳定性,典型方案如"支付指令异步处理+Redis缓存热点数据",可降低主库负载30%以上。
支付结算与异构数据库的挑战
在现代金融科技和电子商务领域,支付结算系统(Payment & Settlement System, PSS)扮演着至关重要的角色,无论是银行、第三方支付平台,还是企业内部财务系统,都需要高效、安全地处理交易数据,随着业务规模的扩大,企业往往需要对接多个异构数据库(如MySQL、Oracle、MongoDB、Redis等),这些数据库在数据结构、查询语言、事务机制等方面存在显著差异,如何实现无缝对接成为技术团队必须面对的挑战。
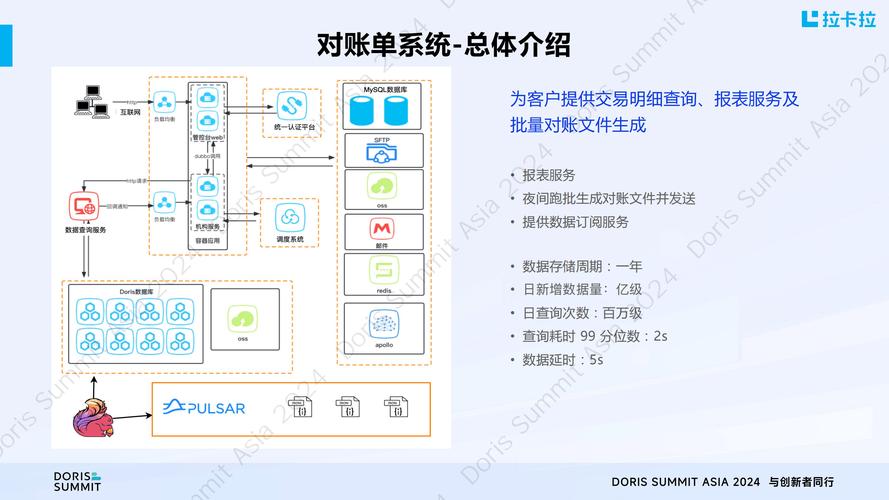
本文将从支付结算系统的核心需求出发,详细解析异构数据库对接的完整流程,涵盖数据同步、事务一致性、性能优化、容灾备份等关键环节,并提供实战案例和最佳实践,帮助开发者和架构师高效完成系统集成。
第一部分:支付结算系统的核心数据需求
1 支付结算系统的典型架构
支付结算系统通常包含以下核心模块:
- 交易处理层:负责接收、校验、路由支付请求。
- 账务处理层:记录资金变动,确保账务一致性。
- 清算对账层:与银行、第三方支付机构对账,确保资金无误。
- 风控与审计层:监控异常交易,保障资金安全。
这些模块通常需要访问不同的数据库:
- 关系型数据库(MySQL、PostgreSQL):存储交易记录、账户余额等结构化数据。
- NoSQL数据库(MongoDB、Redis):缓存高频访问数据(如用户会话、风控规则)。
- 分布式数据库(TiDB、Cassandra):处理海量交易数据,支持水平扩展。
2 异构数据库带来的挑战
- 数据模型不一致:关系型数据库使用表结构,NoSQL可能采用文档或键值存储。
- 事务机制差异:MySQL支持ACID事务,MongoDB仅支持单文档事务,Redis无事务回滚。
- 查询语言不同:SQL vs. NoSQL查询语法(如MongoDB的聚合管道)。
- 性能瓶颈:跨库查询可能导致延迟,影响支付系统的实时性。
第二部分:支付结算对接异构数据库的完整流程
1 需求分析与技术选型
在对接异构数据库前,需明确:
- 数据访问模式:读多写少(适合缓存+数据库) or 高并发写入(需分库分表)?
- 一致性要求:强一致性(如银行转账) or 最终一致性(如电商订单)?
- 扩展性需求:是否需要支持未来新增数据库类型?
推荐方案:
- ETL工具(如Apache Kafka、Debezium):实时数据同步。
- ORM框架(如Hibernate、MyBatis):屏蔽底层数据库差异。
- 分布式事务框架(如Seata、TCC):保障跨库事务一致性。
2 数据同步方案设计
方案1:基于CDC(Change Data Capture)的实时同步
- 适用场景:需要低延迟同步,如支付状态更新。
- 实现方式:
- MySQL → Binlog → Kafka → MongoDB
- Oracle → GoldenGate → Redis
- 优势:近乎实时,对业务代码侵入低。
- 挑战:需处理数据冲突(如唯一键重复)。
方案2:定时批处理同步
- 适用场景:对实时性要求不高,如日终对账。
- 实现方式:
每天凌晨通过Spark/Flink跑批作业,将MySQL数据同步至HDFS,再导入HBase。
- 优势:资源消耗低,适合大数据量场景。
- 挑战:存在数据延迟,需额外校验机制。
3 事务一致性保障
支付结算系统必须确保资金操作原子性,跨库事务的解决方案包括:
- 2PC(两阶段提交):
- 协调者先询问所有数据库能否提交,再统一执行。
- 缺点:阻塞性强,性能较差。
- TCC(Try-Confirm-Cancel):
- 适用于高并发场景,如电商扣库存+支付。
- 示例流程:
- Try阶段:预扣款(冻结用户余额)。
- Confirm阶段:实际扣款(若支付成功)。
- Cancel阶段:解冻余额(若支付失败)。
- SAGA模式:
- 将长事务拆分为多个本地事务,失败时补偿。
- 示例:跨境支付涉及多银行,某一步失败则逆向退款。
4 性能优化策略
- 读写分离:MySQL主库写,从库读 + Redis缓存热点数据。
- 分库分表:按用户ID哈希分片,避免单库压力。
- 异步处理:非核心操作(如短信通知)走消息队列(RabbitMQ/RocketMQ)。
5 容灾与数据备份
- 多活架构:支付系统需支持异地多活,数据库同步通过DRDS或Galera集群实现。
- 备份策略:
- MySQL:每日全量备份 + Binlog增量备份。
- MongoDB:Oplog + 定期快照。
- Redis:RDB+AOF持久化。
第三部分:实战案例——某跨境支付平台的数据库对接
1 业务场景
某平台需对接:
- MySQL:存储用户账户、交易记录。
- MongoDB:存储风控日志(JSON格式)。
- Redis:缓存汇率数据,实时更新。
2 技术实现
- 数据同步:
- 使用Debezium监听MySQL Binlog,将交易数据实时同步至Kafka。
- Flink消费Kafka数据,写入MongoDB(风控分析)和Redis(更新汇率缓存)。
- 事务管理:
采用TCC模式处理“转账+风控审核”跨库操作。
- 性能优化:
Redis缓存用户最近10笔交易,减少MySQL查询。
3 踩坑与解决
- 问题1:MySQL和MongoDB的ID生成策略冲突。
- 解决:统一使用Snowflake分布式ID。
- 问题2:跨境支付时区不一致导致对账错误。
- 解决:所有时间戳存储为UTC,前端按用户时区展示。
第四部分:未来趋势与总结
1 云原生与Serverless数据库
- 趋势:AWS Aurora、阿里云PolarDB等托管数据库降低运维成本。
- 建议:支付系统可逐步迁移至云数据库,利用自动扩展能力。
2 区块链与支付结算
- 探索方向:智能合约自动清算,减少人工对账。
3 总结
支付结算系统对接异构数据库的核心在于:
- 合理选型:根据业务需求选择同步方案(CDC/批处理)。
- 保障一致性:TCC、SAGA等模式确保资金安全。
- 优化性能:读写分离、缓存、异步化是关键。
- 容灾先行:多活+备份避免数据丢失。
通过本文的流程解析和实战案例,希望读者能更高效地完成支付结算系统与异构数据库的对接,支撑业务的快速增长。
本文链接:https://ldxp.top/news/4447.html


