

当代码开始"说话"
凌晨三点,屏幕的蓝光刺得眼睛生疼,第十次测试失败后,我盯着日志里那句冰冷的Connection refused,突然意识到:发卡网的内部通讯模块不是冰冷的代码,而是整个系统的"心跳"。
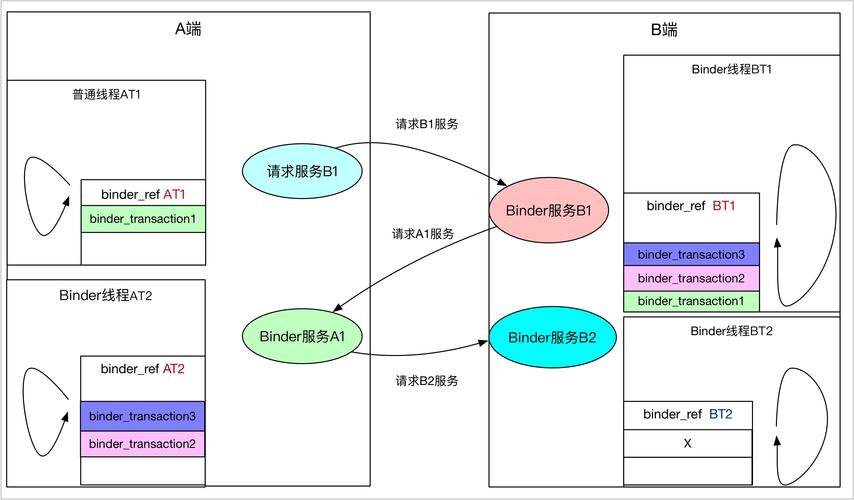
它像一场隐秘的对话——订单服务对库存模块低语:"这个卡密还有吗?"支付模块向风控系统咆哮:"这笔交易可疑!"如果通讯断了,整个系统就成了哑巴,交易卡单、库存错乱、风控失效……用户只会看到"系统繁忙"的提示,而不知道后台正上演着一场通讯灾难。
我想聊聊如何让这场"对话"流畅、安全、高效,这不是一篇干巴巴的教程,而是一个趟过坑的人,和你分享那些深夜debug后的顿悟。
为什么内部通讯是发卡网的"生命线"?
1 对比:理想vs现实的通讯场景
- 理想情况:订单下单 → 库存锁定 → 支付确认 → 卡密发放,行云流水,毫秒级响应。
- 现实情况:
- 订单服务喊了库存模块,但对方"装死"(超时);
- 支付成功了,但卡密没发出去(消息丢失);
- 风控拦截了交易,但订单状态还是"待支付"(数据不一致)。
发卡网的业务特殊性:
- 高实时性:用户付完款,卡密必须秒到;
- 高一致性:绝不能出现"卖了卡密却库存没扣";
- 高容错性:某个服务挂了,不能拖垮整个系统。
2 情绪共鸣:那些年我们踩过的通讯坑
- 案例1:用HTTP轮询查订单状态,结果把数据库查崩了(轮询的代价);
- 案例2:直接调服务A的API,结果A挂了,服务B跟着报错(没有熔断);
- 案例3:日志里全是
TimeoutException,但没人知道是网络问题还是服务真挂了(缺乏监控)。
:内部通讯不是"能跑就行",而是要在速度、可靠性和可观测性之间找到平衡。
通讯模块配置实战指南
1 协议选型:RESTful、RPC还是消息队列?
| 协议 | 适用场景 | 发卡网案例 | 缺点 |
|---|---|---|---|
| HTTP API | 简单查询,低频调用 | 管理后台拉取订单列表 | 性能低,无状态 |
| gRPC | 高性能服务间调用 | 订单→库存的扣减操作 | 需要协议适配 |
| RabbitMQ | 异步任务、削峰填谷 | 支付成功后的卡密发放 | 运维复杂 |
| WebSocket | 实时通知(如订单状态推送) | 用户页面的交易状态更新 | 连接维护成本高 |
个人选择:
- 核心链路(如库存扣减)用gRPC(二进制传输,快);
- 最终一致性场景(如发卡)用RabbitMQ(确保消息不丢);
- 外部通知用WebSocket(用户不想刷新页面等结果)。
2 配置示例:让RabbitMQ在发卡场景中"不丢消息"
# RabbitMQ配置(Spring Boot示例)
spring:
rabbitmq:
host: rabbitmq.internal
port: 5672
username: admin
password: ${RABBITMQ_PASSWORD}
# 关键配置:开启确认和持久化
publisher-confirms: true # 确保消息发到Broker
publisher-returns: true # 路由失败回调
template:
mandatory: true
listener:
simple:
acknowledge-mode: manual # 手动ACK,防止消费失败丢消息
关键点:
- 消息持久化:交换机(Exchange)、队列(Queue)、消息(Message)都要设
durable=true; - 消费端幂等:防止重复发卡(比如用
订单ID+卡密ID做唯一键); - 死信队列:处理一直失败的消息,避免堵塞主队列。
3 容错设计:如何让通讯链路"打不死"?
-
重试策略:
- 指数退避(Exponential Backoff):第一次1秒后重试,第二次2秒,第三次4秒……
- 限制最大重试次数(比如3次),避免无限阻塞。
-
熔断机制(Hystrix或Resilience4j):
// 示例:库存服务调用熔断 @CircuitBreaker(name = "inventoryService", fallbackMethod = "fallbackCheckStock") public boolean checkStock(String cardId) { // 调用库存服务 } public boolean fallbackCheckStock(String cardId, Exception e) { log.error("库存服务不可用,降级返回false", e); return false; // 默认不允许下单 } -
服务发现与负载均衡:
- 用Consul/Nacos做服务注册中心;
- 通过Ribbon或gRPC-LB分摊流量。
那些容易被忽略的"暗坑"
1 网络不是"魔法":超时与序列化
- 超时设置:
- gRPC:
managedChannelBuilder.withDeadlineAfter(500, TimeUnit.MILLISECONDS); - HTTP:
Feign.client.config.default.connectTimeout=2000。
- gRPC:
- 序列化陷阱:
- JSON字段改名导致解析失败(比如Java用
cardType,Go用card_type); - Protobuf字段编号冲突(修改
.proto文件时要谨慎)。
- JSON字段改名导致解析失败(比如Java用
2 日志与监控:给通讯链路装上"X光机"
-
分布式追踪(OpenTelemetry + Jaeger):
# Python示例:追踪gRPC调用 from opentelemetry import trace tracer = trace.get_tracer(__name__) with tracer.start_as_current_span("call_inventory_service"): inventory_client.check_stock(card_id) -
关键指标监控:
- 消息队列积压数(
rabbitmq_queue_messages_ready); - 服务调用成功率(
grpc_client_handled_total); - 平均响应时间(
http_request_duration_seconds)。
- 消息队列积压数(
通讯是艺术,更是工程
配置发卡网的内部通讯模块,就像在搭建一座隐形的桥梁。技术选型是砖石,容错设计是钢筋,监控是照明灯。
我曾因为一个ACK没配置,导致凌晨丢了200单;也曾因加了熔断,在促销时救活了整个系统,这些经验告诉我:好的通讯设计,是让系统"活"起来的关键。
最后送一句深夜debug时的感悟:
"通讯失败的日志里,藏着系统最真实的独白。"
希望这篇手记,能让你少走一点弯路。
你的发卡网,开始顺畅对话了吗? 🚀
本文链接:https://ldxp.top/news/4353.html


